Question.
Answer.01
-
01
“品質の高いデータを確保することが最優先です。”
-
AIがデータを学習するのに使われるINPUT/OUTPUTの品質管理が何より大事です。 INPUTは在職者のAIコンピテンシー検査の結果で、OUTPUTは在職者の人事評価です。
良いモデルとアルゴリズムを使ったとしてもこれらのデータに一貫性や正規性が なければ予測力は低下します。安定的なモデルをつくるためには3段階のプロセスを行います。
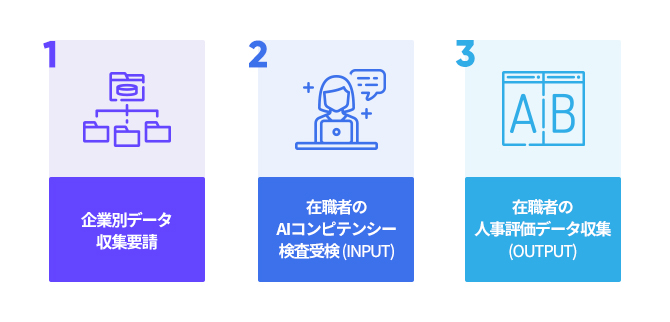
1) 企業別AIコンピテンシー検査要請 企業の採用評価基準をより正確に選出することを目的とし、 まずは在職者のコンピテンシー検査と人事評価データを要請します。
2) 在職者のAIコンピテンシー検査受検(INPUT) 各企業の在職者に、受検案内を行います。 在職者は案内に従い可能な場所と時間にAIコンピテンシー検査を受検します。
3) 人事評価データの収集(OUTPUT) 正規性を想定した4つの評価項目(成果、コンピテンシー、関係、総合)を企業に要請します。 収集した人事評価データを在職者のAIコンピテンシー検査結果と合わせることで、各企業ごとに 在職者の特性を把握する分析を行います。分析結果は貴社の予測モデル及びアルゴリズムの改善に活用されます。
Answer.02
-
02
“AIコンピテンシーモデルは4段階のプロセスから進化し続けています。”
-
AIコンピテンシー検査は以下のような過程で改善を繰り返しています。
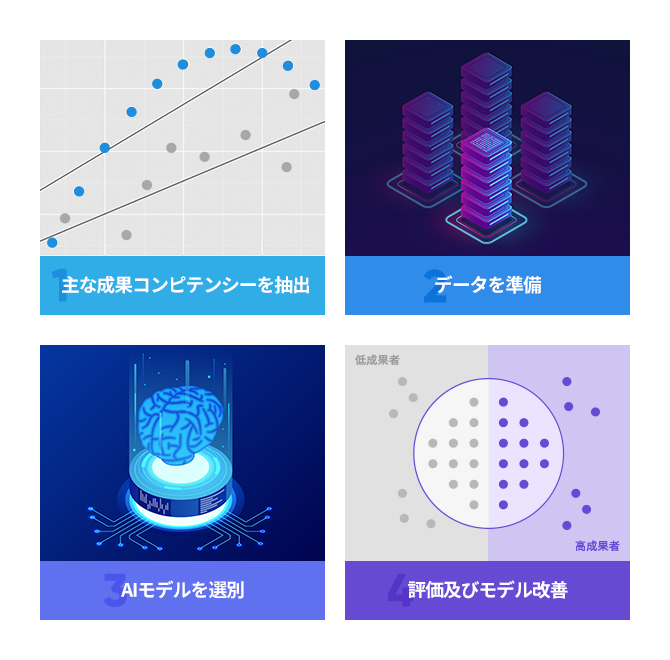
1) 主な成果コンピテンシーの特性及びパターン抽出のためのデータ分析 人口統計学的情報(年齢/性別/職種など)によりデータを細分化し相関分析、 平均差分析など様々な統計分析手法を活用します。そこから、変数別重要度を算出し、モデルに反映する主要変数を抽出します。
2) AI学習用データの準備 機械学習のためにデータを準備します。 データの掃除、併合、エンジニアリング、変形などの作業が含まれます。 範疇型データを数値型データに変更したり、 変数標準化作業などモデル化手法によるエンジニアリング過程が代表的な例となります。
3) AIモデルの選別 データの準備が完了しましたら、モデル化を進めます。 適用するモデルを選択し交差検証のために データをそれぞれ学習用、検証用、テスト用の集合に分離する設計をします。 1,000回以上繰り返し学習をした後、最も高い予測力を示すモデルを選択します。
4) モデルの評価 選定されたモデルに新しいデータを投入し、高/低成果者の分類に 対する精度を確認します。RMSE,Lift,ROCなどのモデル評価指標から、性能を持続的に比較検討しながら、アルゴリズムを改善します。
inAIR FAQ
よくあるご質問です。
その回答をご紹介します。